
It's probably a sick reflection of who I am as a person that while I'm too sick with COVID-19 to find much enjoyment in reading, playing games, or watching movies, that I do apparently find some in building out my blog.
I can't pretend I'm anywhere close to flow or hyperfocus, nor that the effort isn't chaotic and mired in my own dumbness, but I do have an enthusiasm and motivation to actually build this thing out that I haven't had for a long time.
So it's gone for the last few days as I've been recovering. I'm nearly well now, though my brain stubbornly sticks to feeling like I'm the stupidest person on earth, which has led me to making some hilarious choices as I work on what is fundamentally some very basic web development.
Still, progress — and distractions. Let's address those first.
I don't hate containers!
I have until recently felt like the last person alive who doesn't like working with containers. I know their benefits, I recommend their use in every SDLC I've ever supported, and strongly advocate their adoption for all the reasons everyone else does. I just hate working with them.
My main gripe has been with apps that distribute themselves as docker containers. That means they're not in my distro's package manager, not updated automatically when I update everything else, and have to be monitored and maintained in a very different way to everything else on my systems. More than that, they aren't installed or managed in the same way as everything else. Instead of relying on my distro's package maintainers to provide sensible defaults, documentation, and predictably-placed configuration files for me to work with, I instead have to trust some blind commands to pull down containers or write a bespoke and temporary YAML file full of undiscoverable directives that vary from package to package and hides away the configuration of underlying system functionality that everything else uses.
Maybe due to my coronavirus-shaped dumb stupour this past week, I decided to take a bit of a closer look at containers given that they're so admired. Perhaps I had it wrong and it was simply a matter of learning more about them and how to work with them. That was my thought going in, and after some initial reading my hope dwindled to the point where I started to look at alternative implementations.
That's when I learned about Linux Containers (LXC). These aren't containers like I'd used them previously. These are encapsulated and namespaced virtual environments provided by the kernel. They 'feel' a lot like a chroot to work with, or like a small virtual machine. They're very fast, 'booting' instantly, and running just as fast as native execution. Best of all, they're configured and managed using the same sorts of tools and methods as the rest of my system.
It hit me that I didn't hate working with containers; I hated working with Docker containers!
I've since migrated this blog into an LXC container, which I work on locally then push up to rhys.wtf when I finish a feature. Its database and static assets stay outside of the container so I can work on things in isolation when developing without polluting prod or requiring me to clean the container up each time I push. I then separately backup my database/static assets on a nightly schedule and my LXC container each time I push a change.
The drawbacks over Docker containers are twofold: their size, and their toolchains.
LXC containers are big. A barebones Arch container is in the region of 700-800MiB even before any code is written. That makes both the process of compressing them into gzipped tarballs and the upload to rhys.wtf take a while.
The toolchain too is pretty barebones. As far as I can see, there aren't any in-built mechanisms for moving containers around easily. I gather that LXD is the solution for providing a nicer and more fully-featured way of working with LXC containers. Canonical just spun LXD out as an independent project from LXC earlier this month. I may look at it in the future, or I may just build out some automation tooling instead.
All in all, I'm probably using LXC containers in the wrong way here. I've seen LXC described as being 'system' or 'machine' containers, as opposed to Docker's 'application' containers. An application container sounds like the appropriate solution for my web application, and I fully expect that Docker containers would be a better and more efficient choice here.
Still, I like LXC containers and I think I'm going to stick with them. My intent will be to encapsulate all my major applications into them and backup accordingly, which will make my choices around hosting and management in the future pretty uncomplicated.
Backups
Backups are one of those topics that are vitally important but incredibly boring.
I've lived through a number of crucial data losses, both professionally and personally, and consequently I'm one of those people who considers backups an absolute necessity in all circumstances.
The rule of thumb with backups is the 3-2-1 rule, introduced by Peter Krogh in The DAM Book on digital asset management.
Put simply, a good backup strategy should have:
- 3 copies of the data,
- on 2 different media,
- with 1 being off-site.
The rule's origin came before cloud storage became so prevalent, and so many consider it to be too rigorous now. The principle however is to ensure that you have sufficient redundancy in place to guarantee data recovery across multiple risk impact scenarios. Two different media ensures that one disk array failing doesn't trash your whole collection. One copy being stored off-site ensures that a fire in your building doesn't trash every copy you have.
In my case, I'd term my set-up as having 4 primary storage locations, as depicted below:

Here we have:
I have two primary data lifecycle flows to worry about: data originating locally, and data originating on rhys.wtf.
Let's take them one at a time.
Locally-originating data
Most of my data starts on my local machine (or on one of my other devices that I use the magical Syncthing with to sync to my local machine). From there, it gets regularly backed up to my DAS by rclone. On a weekly basis, it then gets backed up to rsync.net using rclone.
1 uses a local NVMe SSD with ext4. No special redundancy or failover or anything present. I have some resilience in the form of my data generally being synced to other devices with Syncthing, but that's not a core part of my backup approach.
2 uses a RAID5 spinning disk array. This can survive any one disk failing, but it is DAS connected to my local machine so could potentially still suffer a catastrophic loss if I accidentally dd if=/dev/zero of=/dev/sda1 or if I get hit by ransomware or similar.
4 is an rclone job to backup from my DAS to rsync.net on a weekly basis. I have it manually configured to create dated copies on overwrite, and rsync.net uses ZFS and provides 7 days of snapshots I can rely on if that somehow doesn't suffice.
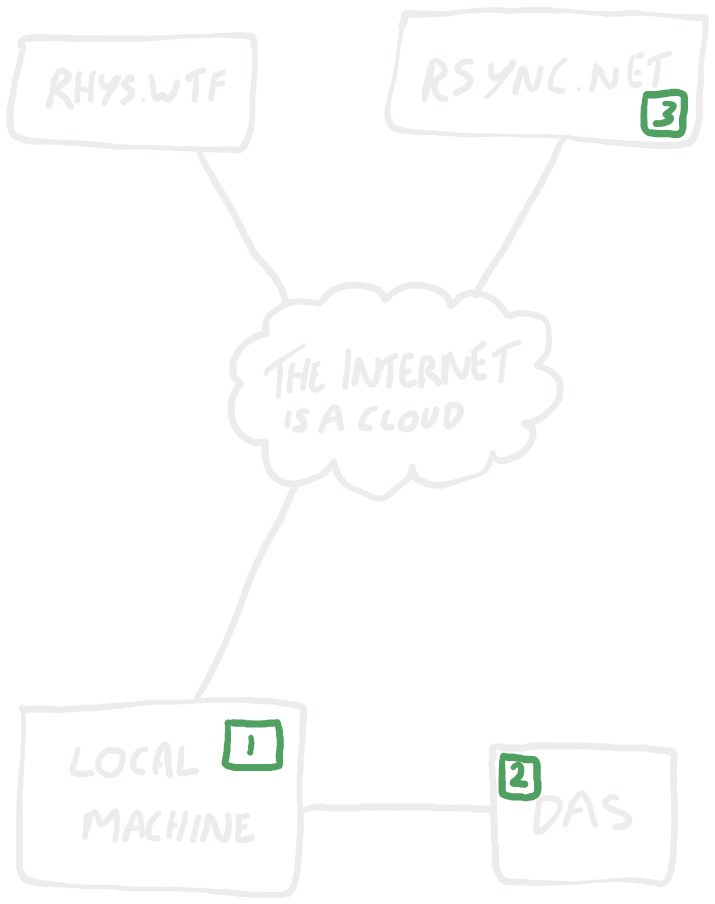
In this scenario, if my local machine dies, I have my DAS. If my DAS dies or my local machine dies in a way that takes out my DAS, I have rsync.net. If I get hit with ransomware and it propagates through to rsync.net, I have my own dated rclone snapshots or their ZFS snapshots to rely on. 3 copies, 2 (or 3, depending on how you view it) media, with 1 off-site.
rhys.wtf-originating data
Here we have data on rhys.wtf. The container for my web application originates locally, as does my code repository, so the only critical data here is the website database and associated static assets. These are currently on the root block volume for my VM, so no direct redundancy.
On a daily basis I rclone my database and static assets to rsync.net. There's no reason this can't be shorter, but at the moment my updates to content here are infrequent since I'm working on the code base. Once I'm up and running, I can make this hourly or even shorter — or maybe build something using inotify (if that's still a thing) to watch for changes and backup whenever something changes.
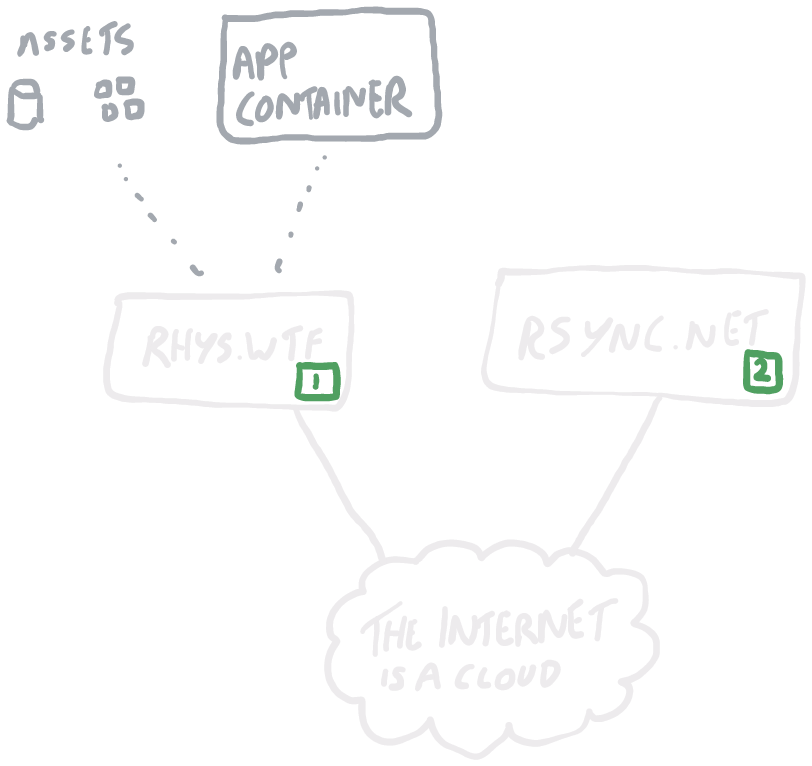
That gives me data in 2 places, on 2 media, with 1 offsite. To fully meet the 3-2-1 rule, I should also clone that static data downward to my local machine. However, given that the static assets will all be photos and diagrams I upload from my local machine anyway — albeit not collected in the same structure, but still reproducible — then my sole exposure is the prod database of post content. That'll get dated instances created on every update, so I think the risk of loss becomes tiny. My exposure is limited to a catastrophic and unrecoverable loss of all data on rsync.net and rhys.wtf.
rclone and rsync.net
I've been using rclone for backups for a long time, and rsync before that. I know there are likely better tools out there nowadays (restic and borg seemingly get the most love), but I've never felt the need to stop using rclone.
The thing I love most about it is it's incredible crypt module. From its documentation:
Accessing a storage system through a crypt remote realizes client-side encryption, which makes it safe to keep your data in a location you do not trust will not get compromised. When working against the crypt remote, rclone will automatically encrypt (before uploading) and decrypt (after downloading) on your local system as needed on the fly, leaving the data encrypted at rest in the wrapped remote.
The crypt module adds a transparent layer to the definition of a remote, which seamlessly encrypts and decrypts data locally whenever sending to or receiving data from that remote. When in use, any files backed up using rclone will be encrypted locally, such that on the remote system they remain in an encrypted state.
I generally have a low level of trust in tech companies to responsibly handle data. My view is that if they can access your data, they will access your data, if not soon then eventually. So, I try to always take the approach of ensuring that they can't access my data, by ensuring it's encrypted prior to being uploaded.
I've used this approach with S3 Glacier for years, and just today I've begun migrating my backup solution to rsync.net as described above. Glacier is vastly cheaper to store, but costly and extremely inconvenient to restore — especially with large volumes of data. I'm at 1.2TiB stored on there currently, and while acknowledging that that's not a huge dataset anymore, it's already sufficiently large that it's a pain to work with. On top of that, my use is changing now as I build my website out and work on a few other things, to the point where more frequent access and monitoring seems more useful to me. Plus I've been on a long-standing quest to get myself away from big tech companies, and this is one of my last hurdles (just my Route 53 domain I'll move when it next expires, and a HomePod I need to sell left).
So, rsync.net fits the bill. It's not ridiculously expensive — though admittedly is more expensive than some dedicated object-store backup services — while presenting solely SSH access to a massive ZFS store, with no fees for ingress/egress, restoration, or anything else. It fits with the tools and methods I'm using already, sits in their own dedicated infrastructure (so I'm not still just using AWS by proxy), and it's fast as hell. I can even use my SSH access to it to have it pull my encrypted files directly from AWS, leaving them in their encrypted state and still compatible with my current rclone setup, without needing to download and reupload files via my local machine.
Actual blog work
And then I come to the blog itself.
It's strange working on a frontend web application again. It's been a long time since I've written any meaningful code in my free time, and longer still since I wrote any professionally. My immediate reflection is that I'd forgotten how much time it takes sometimes working through really silly and trivial issues.
To begin, I have proper photo support in posts now, as demonstrated by my background image here:

The amount of time I spent styling the CSS to make these image divs fit, look right, and work would embarrass anyone. I could blame my covid brain, but I'm pretty sure it's just that I have no idea what I'm doing — as you'll definitely conclude if you check my stylesheet, massive as it is, given I've not bothered to refactor it across pages yet.
Inserting images into posts too was a fun challenge. Django's template language doesn't get parsed when included in model object data, likely by design, presenting the tough challenge of how to embed images in posts. A few solutions exist in the form of WYSIWYG widgets that upload images on the fly as you compose, or I could just write tags with references to images I've already uploaded. However, I want to treat images across the site as semantic objects with all of their extended attributes available to me. In posts like this, their title and captions are important, for example — but later on I want to build out galleries with more meaningful data being important too.
I begrudgingly tried to work with what little JavaScript I could remember from my university days to reanchor images where I wanted. Despite trying to avoid using JavaScript whenever I can, it seemed like the only viable solution. Many hours of struggling with my hilariously inadequate competence, I gave up and accepted some brilliant help from Sam in the form of a custom template tag and some additional template tag parsing.
A little bit more JavaScript crept in with the addition of code blocks too. To demonstrate, a code block using highlightjs demonstrating the aborted image anchoring feature described above:
$(document).ready(function(){
$(".post-body-img-block").detach().appendTo('.img-anchor');
});
On top of that, a little bit of backend work around my model structure for albums and categories. That's the fun stuff, once I'm past these words — getting the gallery implementation together.
This is a longer post than I want to be typical, but I do plan to keep up a tempo of posting about my blog building activities as I go. Aside from keeping me enthused, they give me a regular mode of posting that'll help me as I build features out. Once I have more core functionality in place though, I can start posting about a wider range of topics — hopefully soon, as I don't need to do too much more to segregate content properly.